
Processing 1.4 Million CSV Records in Ruby, fast
Looking at a 50MB CSV file might look like no bit task at first, but after the import runs for over 3 hours with under 20% progress, well then you have a problem and it's time for some parallel processing of the data.


Parsing a CSV file and inserting records into a database isn‘t rocket science and doing it Rails is especially easy. CSV.parse, loop through all the records, and insert them into the database and since this project has 100% test coverage I did of course also write specs for this import. Everything is just great, except it isn‘t.
After the job was running for over 3 hours and didn‘t even process half of the file (I think it barely made it at 20%) holy crap that is slow. Looking at the file size didn‘t really tell me much, 50MB 🤷♂️ who cares right? The servers are quick and big and lot‘s of CPU & RAM. But counting the lines and noticing there are 1.4 Million lines that have to be imported, well this seems like a lot. I could live with it if it was a one-time thing, but it‘s a job that is supposed to run every day and it has to import 9 files of which three are roughly the same size as the one running over 3 hours. Ouch.
Switch to SmarterCSV
The first thought that came to mind was to process the file in parallel in multiple processes or threads. To be able to process the work in parallel I first had to create multiple chunks (arrays) in one large array that I could then pass on to be processed in parallel (more on that in the next section). SmarterCSV is perfect for this job because it has this feature built-in.
Here is a short example:
chunks = SmarterCSV.process(
csv_file,
chunk_size: ENV.fetch('CHUNK_SIZE', 1000).to_i
)
This will process the csv_file and return an array of hashes of 1000 records each. Since I wanted to have this value in some way configurable and I’m running this stuff in Docker, having an ENV variable seemed the way to go.
What's great about SmarterCSV is that it generates hashes with the header names as key, this of course if you don’t have a CSV file that actually is somewhat different, and of course my files are that kind of file. The first line actually isn’t a header file, it’s a record containing a counter of how many data records are in the file. Nothing I haven’t seen before. Let me show you:
C,2
D,1234,1,1,9612,9600,20210101,0,0
D,4321,1,1,9612,9600,20210101,0,0
E
The first line tells me that I have two data records and the last line tells me that there two data records in this file and the last record tells me that the file is finished (EOF would be sufficient but I can live with this)
The problem here is that SmarterCSV would create records like this:
:c => 'D', :2 => '1234'
wtf? Where is the rest of my data? Well, since it parses the first line as header it will process any other line in such a way that there are only two fields.
But fear not, after a session of RTFM it turns out that SmarterCSV has parameters to adjust this behavior.
chunks = SmarterCSV.process(
csv_file,
{
user_provided_headers: [:type, :nr, :min, :max, :exp, :imp, :date, :ret, :split],
headers_in_file: false,
chunk_size: ENV.fetch('CHUNK_SIZE', 1000).to_i
}
)
The solution is to use user_provided_headers in combination with headers_in_file: false otherwise it will complain that the data (of the first line) does not match the user-provided header.
So now we are finally ready for parallel processing.
Parallel GEM to the rescue
If you want parallel processing dead simple then the parallel gem is what you need my friend. It makes it very very very easy to process things in parallel and also very easy to suck up 16GB of RAM, but more on that later.
The idea with parallel gem is that you pass it an array containing multiple arrays of chunks you want to process. For my case, I wanted to spin off multiple processes working on 1000 records each.
chunk=[ [1,2], [3,4] ]
Parallel.each...
Now that the data was served in chunks by SmarterCSV let me pass this to Parallel and get this thing imported.
Parallel.each(chunks, in_processes: p_count, progress: "Importing Data") do |chunk|
create_records(chunk)
end
Very simple isn’t it? It passes a chunk of 1k records each (because that is what I told SmarterCSV to create) and uses p_count processes. My initial value was 8 processes and I will get to the point about memory soon, but first, some other surprises.
The first surprise was that it didn’t do anything, it just waited and crashed after a while with
message type 0x5a arrived from server while idle
The problem is, as explained in this post, that PostgreSQL does not allow you to use the same connection in multiple threads. Bummer.
So the solution is to reconnect to the database, simple right?
ActiveRecord::Base.connection.reconnect!
Ok, but now we’re in business right?
Well, not quite. You see, now the specs started failing. Data that was created with factory bot, now suddenly is gone as soon as you reference it. What gives?
It could only be database cleaner that cleans up data when running tests and looking at rails_helper.rb revealed the problem.
DatabaseCleaner.strategy = :transaction
You see, when running the specs and you spin off a new thread, well, it’s a new thread, a new database connection, so you can’t see the non committed transactions in the database. One way to go is to switch to :truncation instead of :transaction or switch of parallel processing for specs by telling Parallel to run in_processes: 0 which will not spin of new processes (same value works with in_threads)
Now all specs pass, the thing goes into staging and I can finally test with some real data.
But I was in for some new surprises, hurra I like surprises.
First, the whole parallel thing was wrapped in a Transaction block, this was from the first code where I thought it would be great to no leave half imported data around, but having 1.4Million records in a transaction probably isn’t the best idea to start with and now running this import in parallel caused the import to commit at what seemed random times. So, removed the transaction and wrapped it in a rescue block to delete already imported data in case it crashes.
Next run, next surprise. Since there were no transactions, I was expecting to see data, but there was none. Even though data was imported, what the f*?
Remember the database reconnect? Well, this project uses the Apartment gem for multi-tenancy, the call to reconnect resets it back to the public tenant and your data is in the wrong place. To solve this, you just need to switch tenants again.
ActiveRecord::Base.connection.reconnect!
Apartment::Tenant.switch!(Apartment::Tenant.current)
So my create_recordsmethod looks like this now
def self.create_records(chunk)
unless Rails.env.test?
ActiveRecord::Base.connection.reconnect!
Apartment::Tenant.switch!(Apartment::Tenant.current)
end
chunk.each do |data_attrs|
MyModell.create!(data_attrs)
end
end
This will ensure that every 1k Chunk will reconnect to the database and switch to the correct tenant.
Ok then, next run and hurra data is importing and the progress bar is moving. Now we’re in business. Well, nope.
ParallelDeadWorker: ParallelDeadWorker
What the??
Well, look at dmesg of the server showed me that oom killer sacrificed a child and killed my ruby process due to out of memory.
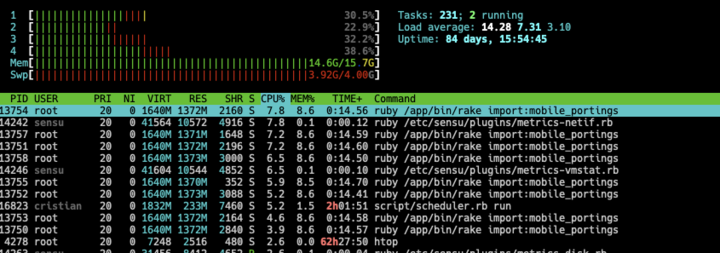
Yeah, I managed to suck up 16GB of RAM and 4GB of swap and get killed in a matter of a few minutes. Ouch. After playing a bit with the value for in_processesI came to a good value of 4, this runs without getting killed on a 16GB VM as well as in a 12GB VM and looking at the resources while it was running showed me that I still do suck up 55% of memory with my ruby process.
The result? Well, that file that took over 3 hours and didn’t manage to be imported in over 3 hours?
It was imported in under 20 Minutes! So from something that would run 6-8 hours down to 20 Minutes, I guess this can be seen as a success and the whole work was worth it.